
Sere directo.
La mayoría de la gente que habla sobre IA suena como si diera definiciones textuales, o simplemente no tiene idea cuando aparecen términos como LLMs o redes neuronales.
No tienes que ser ninguno de esos dos.
Creo que hay cinco términos, cinco conceptos que, si realmente los entiendes (no solo los memorizas), te van a poner muy por delante de casi todos en la sala. Ya sea que trabajes en tecnología, negocios, educación o simplemente tengas curiosidad sobre hacia dónde va el mundo.
Empecemos.
-
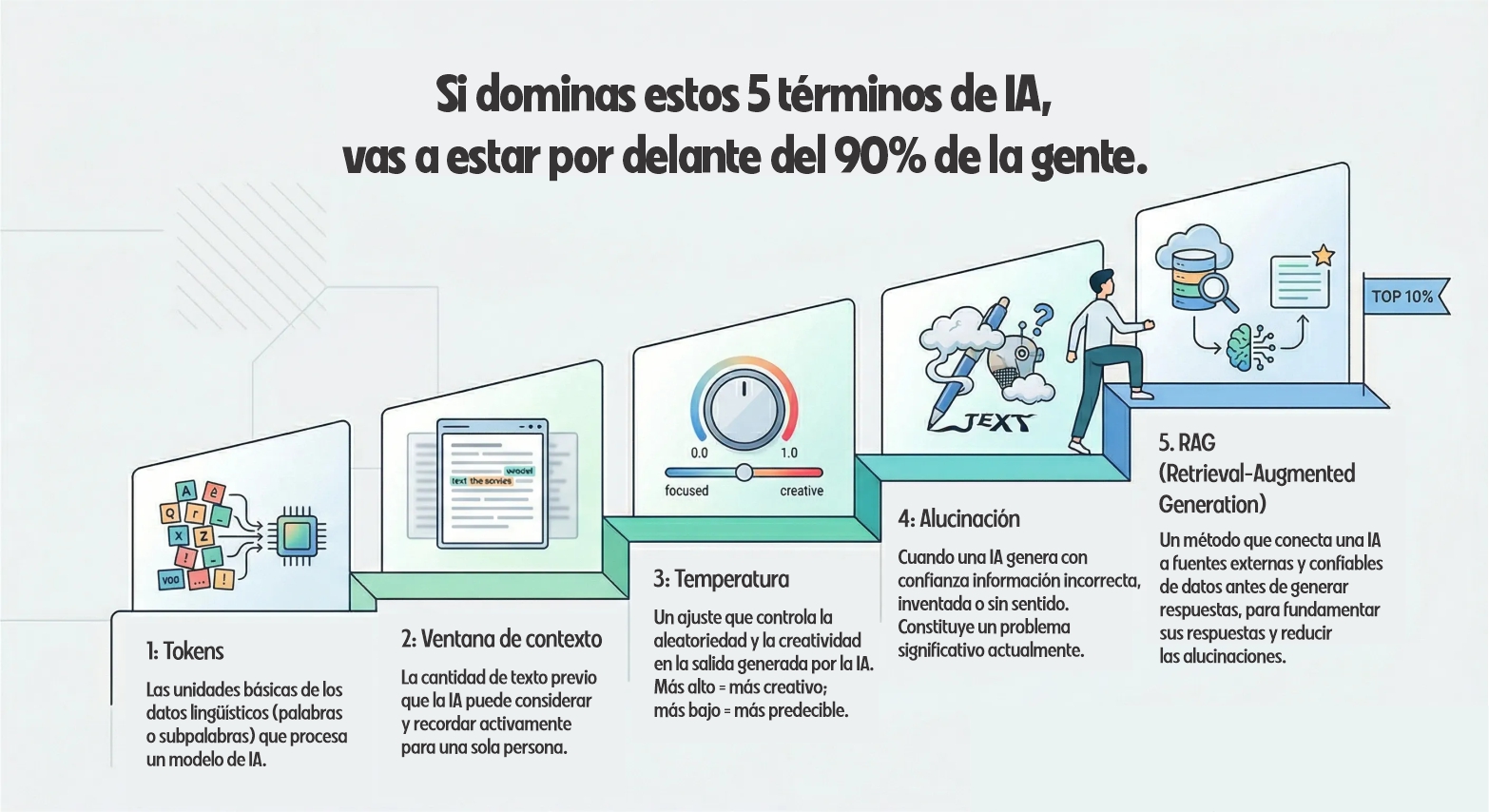
Tokens
Lo primero que debes grabarte en la cabeza es que los modelos de IA no leen palabras. Ni siquiera leen letras. Leen tokens.
¿Y qué es un token?
Imagina que lees un libro, pero en vez de leer palabra por palabra, lees fragmentos. A veces un fragmento es una palabra completa como “gato”. Otras veces es parte de una palabra, como “in” o “ción”. A veces es una puntuación. Ese pedazo de texto (fragmento) es un token.
Por ejemplo, la oración “Me encanta la pizza” se puede dividir en 3 tokens: “Me”, “ encanta”, “ la pizza”.
¿Por qué te importa esto?
Porque cada producto de IA que usas, como ChatGPT, Claude o Gemini, está contando tokens detrás de escena. Mientras más tokens mandes en tu mensaje, más tiene que procesar el modelo. Mientras más tokens genere en su respuesta, más caro resulta ejecutar la consulta.
Cuando escuchas hablar del “context window” de un modelo (más adelante hablamos de esto), se refieren a cuántos tokens puede mantener en memoria a la vez. Algunos modelos antiguos manejaban 4,000 tokens. Los más nuevos pueden manejar más de un millón.
Por eso la IA a veces “olvida” partes anteriores de una conversación larga. Cuando la conversación llena la ventana de contexto, los tokens más viejos se eliminan, como cuando la RAM se llena y tu compu empieza a ponerse lenta.
Los tokens son los átomos del lenguaje en IA. Cuando entiendes eso, empiezas a ver por qué algunos prompts funcionan mejor que otros, por qué la IA se olvida en chats largos y por qué los precios de las APIs se miden en tokens por cada mil. -
Ventana de contexto
Imagina que hablas con alguien que tiene un tipo de memoria muy específico: solo puede recordar los últimos X minutos de la conversación. ¿Todo lo anterior? Se borró.
Esa es la ventana de contexto.
Es la cantidad total de texto, medida en tokens, que un modelo de IA puede ver y considerar al mismo tiempo. Eso incluye todo: tus instrucciones, el historial de la conversación, cualquier documento que hayas subido y las respuestas del propio modelo.
Piénsalo como un pizarrón blanco. La ventana de contexto es el tamaño del pizarrón. Puedes escribir lo que quieras, pero cuando se llena, tienes que borrar algo antiguo para escribir algo nuevo.
¿Qué es lo interesante?
Una ventana de contexto pequeña (por ejemplo 4K tokens) significa que la IA solo puede trabajar con unas pocas páginas de texto a la vez. Si le das un documento largo, solo puede leerlo en trozos. Una ventana grande (por ejemplo 200K tokens) significa que puedes pegar un libro entero y preguntar sobre él.
Por eso la gente se emocionó cuando Claude anunció una ventana de 200,000 tokens, o cuando Gemini empezó a moverse hacia 1 millón. Esto cambia radicalmente lo que puedes hacer con el modelo.
¿La lección práctica? Si trabajas en algo importante, como resumir un documento largo o analizar datos, recuerda que tu IA puede estar olvidando partes anteriores de la conversación. No es un error; es que el pizarrón se quedó sin espacio. -
Temperature (temperatura)
Esta es mi favorita para explicar, porque una vez que la escuchas, no se olvida.
Cuando le pides a una IA que escriba algo, hay un ajuste llamado temperatura que decide cuán aleatoria o predecible será la salida.
Temperatura baja (cerca de 0) = la IA juega seguro. Elige siempre la palabra más probable y esperada. El resultado es consistente, preciso y un poco aburrido. Como ese compa que siempre manda la misma plantilla de email.
Temperatura alta (cerca de 1 o más) = la IA toma riesgos. Escoge palabras sorprendentes, giros inusuales e ideas interesantes. A veces brillante. Otras, no tanto.
Ejemplo real: pide a una IA que “complete la frase: El gato se sentó en el…”
Con temperatura baja, casi siempre dirá “felpudo” o “suelo”. Predecible. Seguro.
Con temperatura alta, podría decir “dilema filosófico” o “imperio desmoronado del martes”.
¿Creativo? Sí. ¿Útil para un informe jurídico? Para nada.
Regla no escrita que pocos conocen:
Si usas IA para tareas factuales como resumir, programar o extraer información, quieres temperatura baja. La IA debe ser precisa, no creativa.
Si la usas para tareas creativas como ficción, lluvia de ideas o copy de marketing, sube la temperatura. Quieres lo inesperado.
La mayoría de apps de consumidor como ChatGPT no te dejan tocar directamente este control; lo ponen en un punto intermedio. Pero si usas una API o una herramienta de desarrollador, verás este ajuste. Y ahora sabes qué hacer con él. -
Alucinación (hallucination)
Este término lo ha escuchado todo el mundo, pero no todos entienden por qué ocurre, y ahí está lo importante.
Alucinación es cuando una IA da respuestas incorrectas con absoluta seguridad. Sin titubeos. Una respuesta falsa presentada como hecho.
Ejemplo: le preguntas a una IA sobre un libro. Te da título, autor, año y resumen de la trama… todo inventado. Ese libro no existe. Pero la IA lo dice como si viniera de Wikipedia.
¿Por qué pasa esto?
La mayoría no lo entiende: los modelos de lenguaje no son bases de datos. No buscan hechos. Predicen el siguiente token más probable según patrones aprendidos durante su entrenamiento. Son autocorrectores gigantescos, a escala masiva.
Así que cuando la IA no sabe algo, no dice “no sé”. Genera lo que suena como una respuesta correcta porque para eso fue entrenada.
El peligro no es que la IA se equivoque — todas las herramientas se equivocan. El peligro es que la IA se equivoque con la misma confianza con que responde cuando tiene la razón. Simplemente contesta.
La lección práctica: nunca confíes ciegamente en la IA para hechos, estadísticas, consejos médicos, legales o cualquier cosa donde un error tenga consecuencias reales. Úsala como punto de partida y verifica.
Quienes entienden las alucinaciones no dejan de usar IA; la usan con más inteligencia. -
RAG
Este es el concepto más malentendido de los cinco. Y la verdad, cuando lo entiendes, lo empiezas a ver en todas partes.
RAG significa Retrieval-Augmented Generation (generación aumentada por recuperación). Es una idea muy simple.
Qué problema resuelve. Un modelo normal fue entrenado con datos hasta cierta fecha. No sabe nada de los documentos internos de tu empresa. No sabe nada de lo que pasó la semana pasada. No sabe nada del PDF que subiste.
Entonces, ¿cómo funciona un producto tipo “Chatea con tu PDF” o “Haz preguntas sobre este documento”?
Esto es RAG.
Cuando subes un documento, el sistema no mete todo en el “cerebro” del modelo. Lo parte en trozos y los guarda en una base de datos especial llamada base de vectores que entiende significado más que palabras clave.
Luego, cuando haces una pregunta, el sistema busca en esa base los trozos más relevantes, los recupera y se los da al modelo junto con tu pregunta, diciendo: “Aquí hay contexto relevante. Ahora responde usando esto.”
Eso es todo. Recuperar lo relevante. Dárselo a la IA. Generar la respuesta. RAG.
¿Por qué importa?
Porque es el esqueleto de casi todos los productos de IA útiles de los últimos dos años. Bots de atención al cliente que conocen las políticas de tu empresa. Asistentes que responden sobre tus documentos legales. Herramientas que resumen artículos científicos. Todo eso se construyó sobre RAG.
Y saber esto cambia tu forma de ver los productos de IA. Cuando una IA “sabe” tus documentos, en realidad no aprendió nada nuevo: hizo una búsqueda muy inteligente y le pasó esos resultados a un modelo de lenguaje. El modelo sigue siendo el mismo; solo cambió el contexto.
Entonces, ¿por qué importa todo esto?
Porque la IA no va a desaparecer. Y la brecha entre la gente que la usa de forma vaga y la que la entiende siquiera a nivel básico será cada vez más importante.
No necesitas ser ingeniero ni escribir código. Pero entender tokens te hará escribir mejores prompts. Entender la ventana de contexto te ayudará a saber por qué tu asistente se confunde. Entender la temperatura te dirá qué ajustes usar según la tarea. Entender las alucinaciones hará que no confíes ciegamente en la IA. Entender RAG te mostrará qué pasa realmente cuando un producto dice “conoce tus datos”.
Eso es todo. Cinco términos. Entendimiento real. Y, honestamente, eso te pone por delante de la mayoría que usa IA sin entender lo que pasa por dentro.
Bienvenido al 10% superior.

